基本概念
Bull是什么?
任务列队一般用于异步处理视频转码,发送短信等耗时任务,不至于API接口连接卡死
Bull是一个Node库,它基于 redis实现了快速而强大的队列系统。
尽管可以使用Redis命令直接实现队列,但是该库提供了一个API,该API可以处理所有底层细节并丰富了Redis基本功能,因此可以轻松处理更复杂的用例。
如果您不熟悉队列,您可能会想知道为什么需要它。队列可以用一种优雅的方式解决许多不同的问题,比如在微服务之间创建健壮的通信通道来平滑地处理CPU高峰,或将繁重的工作从一台服务器转移到许多较小的工作区间等。
开始
安装Bull:
$ npm install bull --save && npm install @types/bull --save-dev
或者
$ yarn add bull && yarn add --dev @types/bull
为了使用bull,你必须先安装Redis.在本地开发环境使用docker可以方便的安装.Bull默认使用 localhost:6379来连接Redis.
简单列队
只需通过实例化Bull实例即可创建队列:
const myFirstQueue = new Bull('my-first-queue');
一个队列实例通常可以有 3 个主要不同的角色:任务生产者、任务消费者或以及事件监听器。
尽管一个给定的实例可用于 3 个角色,但通常生产者和消费者被创建为为多个实例。通过给定队列的例化名称(如上面的示例中的my-first-queue)来引用它,一个列队可以具有许多生产者、许多使用者和许多侦听器。一个重要的方面是,生产者可以添加任务到队列,即使当时没有可用的消费者:队列提供异步通信,这是使它们如此强大的功能之一。
相反,您可以让一个或多个消费者使用队列中的任务,这些任务将按指定顺序消费任务:FIFO(默认值)、FIFO 或根据优先级消费任务。
关于工作区间,它们可以在同一个或不同的进程中、在同一台计算机或群集中运行。Redis 将作为一个公共端点,只要消费者或生产者可以连接到 Redis,他们将能够合作处理任务。
生产者
任务生产者只是将任务添加到队列的一些Node程序,如:
const myFirstQueue = new Bull('my-first-queue');
const job = await myFirstQueue.add({
foo: 'bar'
});
如您所看到的,任务只是一个 javascript 对象。此对象必须可被序列化,更具体地说应该可以被JSON.stringify转化为字符串,因为这就是它存储在 Redis 中的形式。
也可以在任务数据对象参数之后提供一个选项对象参数,后面我们将介绍这一点。
消费者
消费者或工作区间,只不过是一个Node程序,它定义了一个流程函数,如:
const myFirstQueue = new Bull('my-first-queue');
myFirstQueue.process(async (job) => {
return doSomething(job.data);
});
每次工作区间空闲且队列中有任务被等待处理时,都会调用该任务的process函数。由于添加任务时消费者不需要在线(添加和消费是异步的),因此会有许多任务堆积在队列中等待消费,直到全部处理完。
在上面的示例中,我们将process函数定义为 async,这是强烈建议的定义方法。如果您的 Node 运行时不支持异步/等待,那么您只需在进程函数的末尾返回一个Promise,以取得类似的结果。
process函数返回的值将存储在任务job实例中,方便后面可以访问,例如在监听器的completed事件中可以通过progress函数来访问job实例:
myFirstQueue.process( async (job) => {
let progress = 0;
for(i = 0; i < 100; i++){
await doSomething(job.data);
progress += 10;
job.progress(progress);
}
});
监听器
最后,您可以监听队列中触发的事件。如果是本地监听器则只接收在指定的队列实例中生成的通知,如果是全局监听器就会监听指定队列的所有事件。因此,您可以将监听器添加到任何实例,甚至充当消费者或生产者的实例。但请注意,如果队列不是消费者或生产者,则本地事件永远不会触发,在这种情况下,您需要使用全局事件。
const myFirstQueue = new Bull('my-first-queue');
// Define a local completed event
myFirstQueue.on('completed', (job, result) => {
console.log(`Job completed with result ${result}`);
})
生命周期
为了充分利用 Bull 队列的全部潜力,了解任务的生命周期非常重要。从生产者在队列实例上调用add方法的那一刻起,任务进入一个生命周期,该生命周期将处于不同的状态,直到完成或失败(尽管从技术上讲,失败的任务可以重试并获得新的生命周期)。
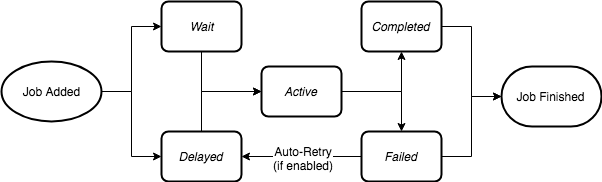
当任务添加到队列中时,它可处于等待状态或延迟状态。等待状态其实是一个等待列表,所有列队在处理之前均处于等待状态,延迟状态意味着任务正在等待某些超时或处理失败的任务,延迟任务不会直接处理,而是在工作区间处于空闲状态时,将其放置在等待列表的开头并进行处理。
任务的下一个状态为"活动"状态。活动状态由一Redis的set集表示,是当前正在处理的任务,这时它们在process函数中运行。任务可以无限时间的处于处于活动状态,直到过程完成或引发异常,以便任务以"已完成"或"失败"状态结束。
停滞任务
在 Bull中,我们定义了停滞任务的概念。停滞任务虽然正在处理的任务,但 Bull 怀疑流程功能已挂起。当process函数正在处理的任务使 CPU 负载过大时,会导致工作区间无法告诉队列它仍在处理该任务,这时会造成停滞任务。
当任务停滞时,根据任务的设置,任务可由其他空闲工作区间重试,也可以切换到失败状态。
停滞任务可以通过确保进程函数不会使 Node 事件循环运行时间太长,或使用单独的沙盒处理器来避免。
事件
Bull 中的队列拥有几个事件,这些事件在许多用例中很有用。事件可以是一个列队实例(一个工作区间)的本地事件,例如,如果一个任务在给定工作区间内完成,则将只为该实例发出本地事件。但是,可以监听所有事件,例如在本地事件名称前加上global:前缀。然后,我们可以监听指定队列的所有工作区间生成的所有事件。
一个本地的completed事件:
queue.on('completed', job => {
console.log(`Job with id ${job.id} has been completed`);
})
而下面这样就可以通过全局来监听:
queue.on('global:completed', jobId => {
console.log(`Job with id ${jobId} has been completed`);
})
请注意,全局事件的签名与本地事件的签名略有不同,在上面的示例中,它只发送任务的 ID 而不是任务本身的完整实例,这样做是出于性能原因。
可用事件的列表可在[reference文档] (https://github.com/OptimalBits/bull/blob/master/REFERENCE.md#eventsk)中找到。
列队选项
队列可以在实例化时可以传入一些选项,例如,您可以指定 Redis 服务器的地址和密码,以及其他一些有用的设置。所有这些设置都在 Bull 的reference文档中找到,下面我们看一下一些选项的用例
更多详细的API请参考文档
速率限制
为创建的队列限制在时间单位中处理的任务数。限制是每个队列定义的,与工作区间数量不一,因此您可以水平缩放,并且仍然能够轻松限制处理速率限制:
// Limit queue to max 1.000 jobs per 5 seconds.
const myRateLimitedQueue = new Queue('rateLimited', {
limiter: {
max: 1000,
duration: 5000
}
});
当队列达到速率限制时,请求的任务将加入delayed队列。
命名任务
可以给任务命名不会改变队列的任何机制,但可获得更清晰的代码以及在UI 工具中的更好可视化:
// Jobs producer
const myJob = await transcoderQueue.add('image', { input: 'myimagefile' });
const myJob = await transcoderQueue.add('audio', { input: 'myaudiofile' });
const myJob = await transcoderQueue.add('video', { input: 'myvideofile' });
// Worker
transcoderQueue.process('image', processImage);
transcoderQueue.process('audio', processAudio);
transcoderQueue.process('video', processVideo);
请记住,每个队列实例都需要为每个命名任务提供一个处理器,否则将抛出异常。
沙盒处理器
如上所述,在定义process函数时,还可以提供并发设置。此设置允许工作人员并行处理多个任务。任务仍在同一Node进程中处理,就算处理的OI密集非常高的任务也会处理正常。
但是有时需要处理CPU密集非常高的任务,这可能会锁定Node事件循环太久而导致Bull 可能会停止任务。为了避免这种情况,可以在单独的Node进程中的运行process函数。在这种情况下,并发参数将决定允许运行的并发进程的最大数量。
我们称这种进程为"沙盒"进程,这样就算某个进程崩溃也不会影响任何其他进程,并且将自动生成一个新进程来取代它。
任务类型
Bull 中的默认任务类型是"FIFO"(先出),这意味着任务的处理顺序与进入队列的顺序相同。按不同顺序处理任务时这很有用。
LIFO
Lifo(最后一个先出)表示任务被添加到队列的开头,因此将在工作区间空闲时进行处理。
const myJob = await myqueue.add({ foo: 'bar' }, { lifo: true });
延迟
使任务在处理之前延迟一定时间。请注意,延迟参数表示任务在进行处理之前等待的最短时间量。延迟时间过时,任务将移动到列队的开头,并在工作区间空闲时进行处理。
// Delayed 5 seconds
const myJob = await myqueue.add({ foo: 'bar' }, { delay: 5000 });
优先级
任务可以设置优先级。优先级较高的任务将在优先级较低的任务之前进行处理。最高优先级为 1,数值越大优先级月底。请记住,优先级队列比标准队列慢一点(因为优先级列队的当前插入时间 O(n)的会替代标准队列的O(1))。
上面括号中的n 代表当前在队列中等待的任务数
const myJob = await myqueue.add({ foo: 'bar' }, { priority: 3 });
重复
可重复任务是特殊任务,根据 cron 规范或时间间隔,可以无限期地重复,直到给定的最大时间或到达重复次数才停止(如果设置这两者的话)。
// Repeat every 10 seconds for 100 times.
const myJob = await myqueue.add(
{ foo: 'bar' },
{
repeat: {
every: 10000,
limit: 100
}
}
);
// Repeat payment job once every day at 3:15 (am)
paymentsQueue.add(paymentsData, { repeat: { cron: '15 3 * * *' } });
关于可重复任务,有一些重要的注意事项:
- 如果重复选项相同,Bull 不会添加相同的可重复任务。(注意:任务 ID 是重复选项的一部分,因为:https://github.com/OptimalBits/bull/pull/603,因此传递任务 ID 将允许在队列中插入具有相同 cron 的任务)
- 如果没有正在运行的工作区间,则下次工作区间在线时,可重复任务将不累积。
- 可重复任务可以通过 removeRepeatable方法删除
如何使用
基本使用
var Queue = require('bull');
var videoQueue = new Queue('video transcoding', 'redis://127.0.0.1:6379');
var audioQueue = new Queue('audio transcoding', {redis: {port: 6379, host: '127.0.0.1', password: 'foobared'}}); // Specify Redis connection using object
var imageQueue = new Queue('image transcoding');
var pdfQueue = new Queue('pdf transcoding');
videoQueue.process(function(job, done){
// job.data contains the custom data passed when the job was created
// job.id contains id of this job.
// transcode video asynchronously and report progress
job.progress(42);
// call done when finished
done();
// or give a error if error
done(new Error('error transcoding'));
// or pass it a result
done(null, { framerate: 29.5 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
});
audioQueue.process(function(job, done){
// transcode audio asynchronously and report progress
job.progress(42);
// call done when finished
done();
// or give a error if error
done(new Error('error transcoding'));
// or pass it a result
done(null, { samplerate: 48000 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
});
imageQueue.process(function(job, done){
// transcode image asynchronously and report progress
job.progress(42);
// call done when finished
done();
// or give a error if error
done(new Error('error transcoding'));
// or pass it a result
done(null, { width: 1280, height: 720 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
});
pdfQueue.process(function(job){
// Processors can also return promises instead of using the done callback
return pdfAsyncProcessor();
});
videoQueue.add({video: 'http://example.com/video1.mov'});
audioQueue.add({audio: 'http://example.com/audio1.mp3'});
imageQueue.add({image: 'http://example.com/image1.tiff'});
使用promises
你可以返回 promises来替代 done 回调函数:
videoQueue.process(function(job){ // don't forget to remove the done callback!
// Simply return a promise
return fetchVideo(job.data.url).then(transcodeVideo);
// Handles promise rejection
return Promise.reject(new Error('error transcoding'));
// Passes the value the promise is resolved with to the "completed" event
return Promise.resolve({ framerate: 29.5 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
// same as
return Promise.reject(new Error('some unexpected error'));
});
独立进程
process函数可以运行在独立进程中 . 这样做有一下几个优点:
- 进程是一个沙盒,所以就算崩溃也不会影响其它程序工作。
- 你可以在不影响列队的情况下运行阻塞代码 (任务不会停滞)。
- 多核CPU的利用率要好得多。
- 与Redis的连接更少。
要运行此功能只需要创建单独的文件:
// processor.js
module.exports = function(job){
// Do some heavy work
return Promise.resolve(result);
}
并定义处理器,像这样:
// Single process:
queue.process('/path/to/my/processor.js');
// You can use concurrency as well:
queue.process(5, '/path/to/my/processor.js');
// and named processors:
queue.process('my processor', 5, '/path/to/my/processor.js');
重复任务
任务可以添加到队列中,并根据 cron 规范重复处理:
paymentsQueue.process(function(job){
// Check payments
});
// Repeat payment job once every day at 3:15 (am)
paymentsQueue.add(paymentsData, {repeat: {cron: '15 3 * * *'}});
在此处检查表达式以验证它们是否正确
暂停 / 恢复
A queue can be paused and resumed globally (pass true to pause processing for
just this worker):
可以全局暂停和恢复队列(通过此工作区间的暂停处理):true
queue.pause().then(function(){
// queue is paused now
});
queue.resume().then(function(){
// queue is resumed now
})
事件
队列会触发一些有用的事件,例如...
.on('completed', function(job, result){
// Job completed with output result!
})
有关事件(包括已触发事件的完整列表)的信息,请查看事件参考
队列性能
队列很便宜,因此如果您需要其中的许多队列,只需创建具有不同名称的新队列:
var userJohn = new Queue('john');
var userLisa = new Queue('lisa');
.
.
.
但是,每个队列实例都需要新的Redis连接,查看如何重用连接,或者您也可以使用命名任务来实现类似的结果。
群集支持
从版本 3.2.0 及以上版本,建议使用线程处理器。
var
Queue = require('bull'),
cluster = require('cluster');
var numWorkers = 8;
var queue = new Queue("test concurrent queue");
if(cluster.isMaster){
for (var i = 0; i < numWorkers; i++) {
cluster.fork();
}
cluster.on('online', function(worker) {
// Lets create a few jobs for the queue workers
for(var i=0; i<500; i++){
queue.add({foo: 'bar'});
};
});
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
}else{
queue.process(function(job, jobDone){
console.log("Job done by worker", cluster.worker.id, job.id);
jobDone();
});
}
官方文档
有关完整文档,请查看官方wiki


